|
|
|
�
| Object Import: General Overview |
|
|
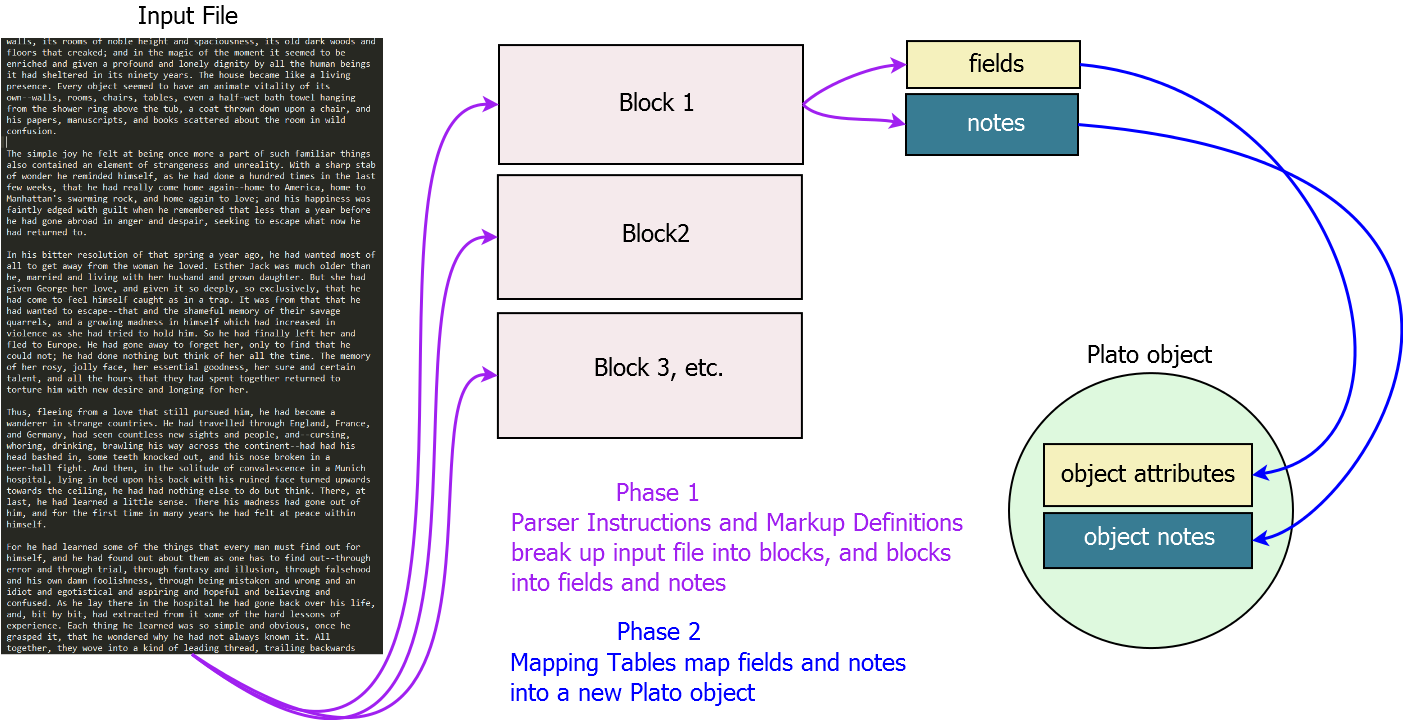
| Figure 1: Path of An Import Script |
|
Importers are a set of instructions for reading files that are external to Plato and importing them into Plato objects. Plato objects consist of field attributes and notes, so the task of a importer is to break the file up into 'records' that will correspond to Plato objects, and analyze each record to determine which portions of it are field attributes and which are notes. It then further analyses the list of field attributes and assigns each to an object's specific field attributes.
Importers can do simple clean-ups on files. Unwanted characters can be stripped or replaced; large text fields can be word wrapped.
Plato importers are designed to be general purpose and can serve many applications, but they are not a substitute for parsing engines that are dedicated to a single format such as such HTML, RTF, or the many varieties of XML.
Importers are stored in the markup section of class libraries. Pressing the 'edit markup' button will load the importer for editing and place into the markup editor.
What the Importer Does
The importer takes structured information from an external file and imports it to Plato objects in three steps: - The Plato importer uses markup to determine how a file is structured so that it may divide the file up into "blocks." Each block will form the raw material for a Plato object, of the class specified in the markup.
- Once the importer has divided the file into blocks, it then goes through the list of blocks and parses each block for fields and notes. How it parses the fields will depend on a particular file's format. Some files (such as email) will have a field section and a note section. Other files, such as spreadsheets, will only have fields, one of which may qualify as a note. Other files will have blocks that will only be broken up into notes. Once fields have been obtained, some may have field names assiciated with content, others only content without associated names. Your import markup will have to define fields and markup in accordance with the conventions of a particular file's format.
- Once fields and notes have been obtained from a block, the field information is gathered into an array where it is validated against the mapping table in your markup and then mapped to the appropriate attributes in your new Plato object, and the import is completed.
|
|
| Approaches to Importing |
Importers may be written with a great deal of flexibility but some structure must be present in the file so that the importer has something to work with. Typical files amenable to parsing are: emails or email folder files, web pages and other HTML or XML files, spreadsheet CSV files, and database query result files. Some binary files can be parsed as well, though their structure must be precisely known in order to get meaningful results.
Text files that have no regular structure can still be parsed and imported, provided you don't mind marking them up first and writing your importer to match the markup you've used.
The key to successful importing is to look at the source file to see how it is structured, then write the importer to match that structure. Let's take two examples.
The first is relatively straightforward-- the standard comma seperated value (CSV) file. Here are a few lines from such a file:
"Mojoworld","","Pandromeda","game, simulation"
"Nikon Scan","","Nikon","editor, image"
"Wikipad","1.16","Jason Horman","editor, outliner"
"Chview","","","mapping, astronomical"
Looking at this type of a file will show you that each line is a 'record.' There is no start-of-record marker; the end-of-record marker is a line break. Within each record, fields are seperated by commas. Fields may also be enclosed in quotes if the text in the field contains commas that should not be confused with the commas that seperate the fields. The names of the fields are not contained in the records, so the importer will have to know what they are (or should be) and assign them.
Here is a sample importer for a CSV file:
[INSTRUCTIONS]
block_mode= line
block_composition = fields
block_mark_mode = end_of_line
field_mode= delimited_no_fieldname
[MARKUP_DEFINITIONS]
end_of_line = &end_of_line
field_end_delimiter = &comma
field_braces = "es
[FIELD_SEQUENCE]
1 = {Author}
2 = Editor
3 = Translator
4 = {Title}
5 = {Subtitle}
6 = Publisher
7 = Year
The second example is a BibTeX formatted bibliography. This also has a standard record/field structure, but it is more complex than the CSV file. Here's a record from such a file:
@book{taylor_ethics_1985,
address = {Englewood Cliffs N.J.},
title = {Ethics, faith, and reason},
isbn = {9780132905527},
publisher = {Prentice-Hall},
author = {Richard Taylor},
year = {1985}
}
Notice that the 'record' in a BibTeX file can be many lines long, and that the fields in the record contain both the contents of the field and the name of the field. The start-of-record marker is a BibTeX keyword bracketed by '@' and a left curly brace '{'. The end-of-record character is a right curly brace '}'. Within the record, fields are seperated by commas. Within the field, the field name is seperated from the field contents by '='.
When field contents may contain commas or equal signs, they may be bracketed with quotation marks or curly braces.
There are some potential parsing problems here that must be addressed. Since curly braces may be used both as record markers and field content brackets, the importer must be told to keep track of them so it won't forget which is which. (This can be done by telling the importer to track braces and giving it a list of the braces to track.)
Another potential problem is that BibTeX field names are generally intended to follow a convention, and so the importer should ensure that the convention is followed.
Here are the instructions from an importer that would parse the BibTeX record above:
[INSTRUCTIONS]
block_mode= block
block_composition = fields
block_mark_mode = start_and_end_tags
field_mode= delimited_with_fieldname
[MARKUP_DEFINITIONS]
block_markers = @book{|}
field_end_delimiter = &comma
field_braces = {}
field_seperator = =
strip_chars_from_block = &control &spaces
[FIELD_SUBSTITUTION]
title = {Title}
author = {Author}
publisher = Publisher
year = Year
These are a couple of examples of standard file structures. A little more imagination may be required if the file structure is not standard. The basic questions to be answered are:
- How are 'records' to be defined in the file?
- How are fields defined?
- Do fields contain names along with content?
- Will matching braces need to be kept track of?
- Should field names be validated?
Remember that the ultimate goal is to import the data into Plato objects, so look at possible ways of defining records and fields with this outcome in mind.
Rather than agonize over writing a importer to cover all the contingencies of a bizarrely structured file, remember that it may be easier to add consistent markup to the file yourself, then write a simple importer to take care of it.
|
|
| Using the Markup Editor for Importers |
|
|
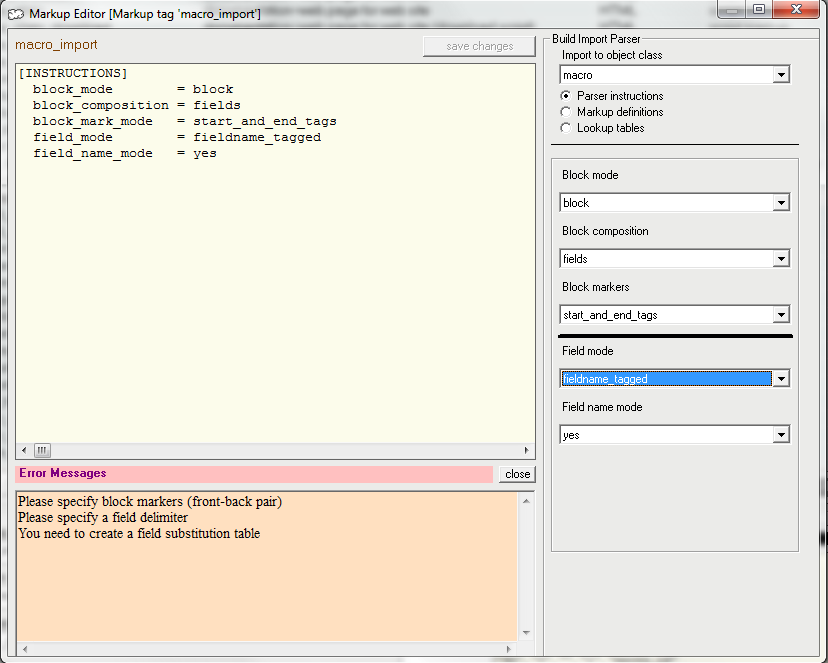
| Figure 2: Markup Pane: Object Imports |
|
The markup editor import pane (see figure 1) consists of a text pane on the left showing the markup text and a set of markup controls on the right. Import markup consists of three sections:- Parsing Instructions Parsing instructions tell Plato how the external file is constructed: how records are to be distinguished, what records contain, how fields are distinguished from each other within a record.
- Markup Definitions Markup definitions give the specific text Plato is to look for to determine the start and end of records and the fields and notes they contain.
- Mapping Tables Mapping tables define how the fields and notes extracted from records are mapped to Plato objects.
Select the controls for each section by pressing the appropriate radio button in the top right portion of the markup pane. You must also select the object class for the objects the importer will create. Use the dropdown list above the radio buttons to select.
Note that markup text for importers is not editable; rather it must be generated by the set of markup controls. While generating the markup text, Plato will give you a running list of errors and remaining things to do to complete the markup.
|
|
| Parsing Instructions |
|
|
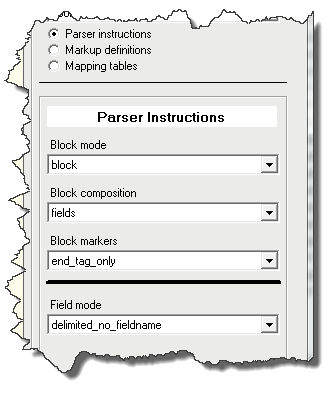
| Figure 3: Import Panes: Instrucvtions, Markup Definitions, Order Tables |
|
Parsing instructions define how input data from a file will be split up into blocks, fields, and notes, which can in turn be placed into Plato objects. There are four controls provided to do this:- Block Mode
- Block Composition
- Block Markers
- Field Mode
Block Mode
Plato importers work with 'blocks' of text that they extract from files. They use one of four modes for obtaining these blocks: line, block, chunk, and file mode.
- Line mode reads the file and looks for end-of-line markers. Each line goes into a block.
- Block mode reads the file and looks for block markers. Everything between the markers goes into a block.
- Chunk mode is for binary files and works by pointing to a file offset and grabbing a chunk of the file of the length you've specified. Chunk mode should only be used on binary files with embedded plain text information.
One chunk mode method is to go to a specified location in the file and grab one chunk of text. This is useful for reading text information from binary file headers if you know where to find that information.
Another chunk method is to start at a particular location in the file and sequentially read chunks of the specified length until the end of the file is reached. This approach may be useful for small flat-file databases that have fixed record and field lengths. It is also useful for going through a binary file whose structure is unknown and extracting all the text strings. - File mode takes the whole file and puts it into a block.
Block Composition
This tells the importer what to look for in the blocks. Three choices:- Fields Tells the importer to break the block up into fields using specified field markers.
- Notes Tells the importer to consider the whole block a note field.
- Fields and Notes Tells the importer to break up the block into a fields section and a notes section, then further break up the fields section into fields using specified field markers.
Block Markers
This tells the importer what to look for in the blocks. What constitutes block markers differs depending on the block mode, however.- Line mode
- end of line This tells the importer to look only for a marker at the end of each block, which in this case is the end of a line. The entire line up to the end-of-line marker will become a block.
- Block mode
- start tag only This tells the importer to look only for a marker at the start of each block. The material between any two start markers will become a block. Material between the last start marker and the end of the file will be placed in a block, but material before the first start marker will be discarded.
- end tag only This tells the importer to look only for a marker at the end of each block. The material between any two end markers will become a block. Material between the start of the file and the first end marker will be placed in a block, but materials between the last end marker and the end of the file will be discarded.
- start and end tags This tells the importer to look for a start marker and an end marker and place what is found between them in a block. Any material outside of what is defined by the start block/end block pairs will be discarded.
- Chunk Mode
- start at offset Tells the importer to go to a specified location in the file (the offset) and grab a specified number of bytes for placement in a block.
- start at offset+ Same as start at offset, except continues through the file grabbing the specified number of bytes and putting them in blocks until the end of the file is reached.
- start at tag Tells the importer to find a specified tag (an arbitrary series of characters you define) and, starting from there, grab a specified number of bytes for placement in a block.
- start at tag+ Same as start at tag, except continues through the file grabbing the specified number of bytes and putting them in blocks until the end of the file is reached.
- File Mode
- start at line Optional. Tells the importer to start at a specified line and grab the rest of the file for the block. If this option is nmot used the whole file is assumed to be the block.
Field Mode
This tells the importer how to get the fields out of a block. Fields can be present as untagged data or as data tagged with a fieldname. There are a number of field mode options for trying to pull fields out of a block of text, depending somewhat on how the text blocks were extracted. Field modes also directly determine which mapping table will be necessary to map the fields to Plato object attributes.- delimited_no_fieldname Fields are seperated by a delimiter such as a comma or a tab (although a delimiter can be one alphanumeric or punctuation character, or can be a combination of several characters including words, phrases, or language tags). The field data between the delimiters contains no filename information and this mode therefore requires a field_sequence mapping table to map the fields to Plato attributes.
- delimited_with_fieldname Same as delimited_no_fieldname except the field data also contains fieldname information. delimited_with_fieldname mode therefore requires that you specify a field_seperator marker to distinguish the field data from the fieldname data. It also requires a field_substitution mapping table to map the fieldnames in the data to attribute names in the Plato destination object.
- delimit_embedded_fieldname Same as delimited_with_fieldname except the fieldname is not contained in the field data, but is rather embedded in the delimiter.
- tagged_no_fieldname Fields are enclosed within a pair of tags termed start and end tags. The field data between the pair of tags contains no filename information and this mode therefore requires a field_sequence mapping table to map the fields to Plato attributes.
- tagged_with_fieldname Same as tagged_no_fieldname except the field data also contains fieldname information. tagged_with_fieldname mode therefore requires that you specify a field_seperator marker to distinguish the field data from the fieldname data. It also requires a field_substitution mapping table to map the fieldnames in the data to attribute names in the Plato destination object.
- tag_embedded_fieldname Same as tagged_with_fieldname except the fieldname is not contained in the field data, but is rather embedded in the start tag.
- line_offset This mode addresses text files in which fields are laid out in fixed-length columns in a line, and each line is a fixed-lengh record. The columns are padded with spaces to achieve equal width. There are no tags or delimiters so fields are determined strictly by their position along the line. line_offset mode therefore requires only a line_offset table to map the fields to Plato attributes according to their position in the fixed-length record.
- length_offset This mode addresses
|
|
| Markup Definitions |
|
|
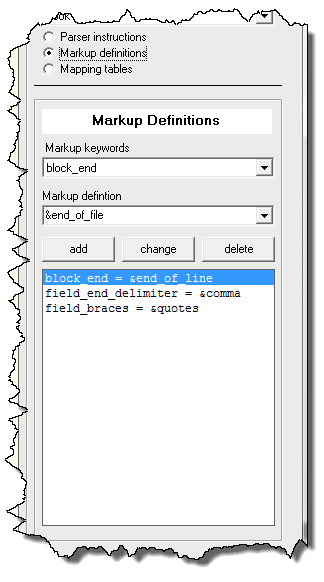
| Figure 4: Assigning Markup Definitions |
|
Markup definitions support parsing instructions by defining exactly what markup to look for in the input file that determine blocks, fields, and notes. Markup Definitions may be line offsets, delimiter characters such as commas or tabs, or specified pairs of tags such as . Plato macros may often be used instead of literal strings.
Markup for Blocks
Here are the markup definitions necessary to define blocks:- block_start, block_end markers Defines the marker that represents the start or end of a block. A marker can be any single character or set of characters. Any number of markers can be specified, but start and end markers can't be mixed in one set of markup.
- block_markers Defines a pair of markers that enclose a block. Such a pair consists of a start marker and an end marker on one line seperated by a vertical mark (|). Any number of block marker pairs can be specified, but they can't be mixed with block start or block end markers.
Markup for Fields and Notes
Here are the markup definitions necessary to define fields and notes:- note_delimiter Defines the marker that seperates fields from notes in block. Few file formats will have note delimiters but some do. The raw email format is one of the few that does, and uses a blank line (&end_of_paragraph is a Plato macro that represents this) to seperate the email header (which contains fields) from the body (which contains a block of text).
- field start, field end delimiters Field delimiters seperate one field from another in a block. Common field delimiters are commas, tabs, and spaces. These are generally 'field end' delimiters in Plato terminology since they are placed at the end of a field (except for the last field).
Field start delimiters are less common, but an email header is a good candidate for them, which would be the email header field names followed by a colon. This is also a good example of field delimiters with embedded field names.
Message-ID: <4.1.20000226171947.00935630@mail.well.com>
Date: Sat, 26 Feb 2000 17:21:12 -0800
Reply-To: "H-NEXA: the Science-Humanities Convergence Forum"
Sender: "H-NEXA: the Science-Humanities Convergence Forum"
From: "Smiley Hamburguesa"
Subject: SUBJECT: The Gospel according to Science [hbe-l]
To: H-NEXA@H-NET.MSU.EDU
X-UIDL: 53938ef43ccdb961435520d46578aec2
The import markup for this would have several markup delimiters:
field_start_delimiter = Message-ID:
field_start_delimiter = Date:
field_start_delimiter = Reply-To:
field_start_delimiter = Sender:
field_start_delimiter = From:
field_start_delimiter = Subject:
field_start_delimiter = To:
field_start_delimiter = X-UIDL:
- field tag pairs Defines a pair of markers that enclose a field. Such a pair consists of a start marker and an end marker on one line seperated by a vertical mark (|). Any number of field marker pairs can be specified, but they can't be mixed with block start or block end markers.
- fieldname seperator Defines a marker that seperates a fieldname (on the left) from the field contents (on the right). Any number of fieldname seperators can be specified.
- field braces Sometime fields are also enclosed in quotes or other pairs of braces when they contain characters that might be confused with delimiters. The braces "protect" the field contents from this sort of misapplication. Braces are specified in pairs. Several brace pairs can be specified on one line so long as each pair is seperated from the next by a space. Here's an example of a field braces markup definition ('"es' is a Plato macro that expands to a pair of quotes):
field_braces = "es <> {} [] ()
Markup for Cleanups
Markup for cleanup lets you remove unwanted characters or words from blocks or fields as you import them. Markup can be specified for blocks, fields, notes or all three. If for blocks, the cleanup will be performed before the block is parsed for notes and fields. Likewise for fields and notes: the cleanup will be performed before field blocks are parsed for fields or notes are further processed. Cleanup markup instructions are performed in this order:- blocks
- fields
- notes
Within each of these categories, instructions to strip characters, words, or tags are performed in the order they are encountered in the markup list. This means you should give the order of your stripping instructions some thought. If, because of the order of your instructions, you strip the characters before the tags (for instance), and one of the characters you strip is a tag delimiter, your tag strip instruction won't find any tags to strip! And your fields or blocks will have the remanents of corrupted tags strewn through them.
Here are the possible markup definitions for cleanup: - strip_chars_from_block
- strip_words_from_block
- strip_tags_from_block
- strip_chars_from_field
- strip_words_from_field
- strip_tags_from_field
- strip_chars_from_note
- strip_words_from_note
- strip_tags_from_note
- discard_block_if_word
Here are some notes on the conventions for stripping:
Stripping tags Tags should be specified strictly by the brackets that contain them, such as "<>". The tag stripping instruction looks only for the first bracket, then the second, and deletes everything between them along with the brackets. If you only want to strip a particular tag, such as "<table>", use a word stripping instruction to do this (and be sure the word stripping instruction comes before the tag stripping instruction). More that one tag pair can be specified on a line; seperate them with spaces.
Stripping words "Words" are any sequence of non-space characters. Several words can be specified on a line; seperate them with spaces.
Stripping Characters Any number of characters can be specified on a line. Whole categories of characters can be specified using Plato macros.
Here is an example of stripping instructions used to remove all HTML code from an email:
strip_tags_from_note = <>
strip_words_from_note = > " < º · ´ ¯ ¸
strip_chars_from_note = &control &spaces &CRFLs
This example first removes all the HTML tags, then all the HTML escape sequences, then all the extra spaces and line-ends that were left over when the tags were removed (plus any unwanted control characters that may have been present).
Filtering and Discarding Blocks The following markup instructions can be used to discard blocks that contain certain words.
discard_block_if_word = bingbot
discard_block_if_word = googlebot
discard_block_if_word = semrushbot
discard_block_if_word = ahrefsbot
discard_block_if_word = yandexbot
The import script will scan each block for any of the listed words, and if found, the block will be discarded from the output. Multiple discard words can be listed in a single instruction, each word seperated by a space, as follows:
discard_block_if_word = bingbot googlebot semrushbot
discard_block_if_word = ahrefsbot yandexbot
|
|
�
| Special Markup for Spreadsheet Input |
|
|
| Figure 5: Column Heading Spreadsheet Convention |
|
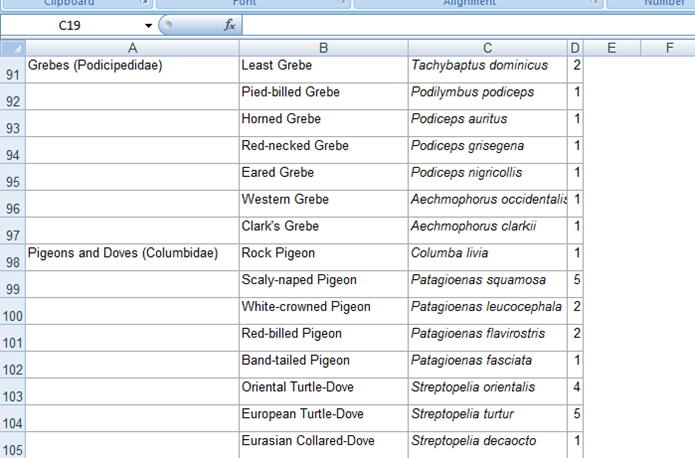
A common spreadsheet convention is to use a cell as a heading for related cells in the next column, and leaving the cells under the heading blank until the next heading is encountered. See column A in Figure 5 for an example of this. Unfortunately, when such a spreadsheet is imported into Plato, the data that is visually implied in the spreadsheet will simply be empty fields in the Plato database. Here's a special markup instruction intended to alleviate this problem:
use_last_nonblank_for = 1 2 4 5 8
where "1 2 4 5 8" are the spreadsheet columns where the instruction is to apply. For the specified columns, the import script will fill the blank Plato fields with the data from the last non-blank cell, until the next non-blank cell is encountered and data from it will be used to fill subsequent blank Plato fields, and so on.
|
|
�
| Mapping Tables |
|
|
| Figure 6: Mapping Tables: Field Substitution, Field Sequence, Line Offset, Length Offset |
|
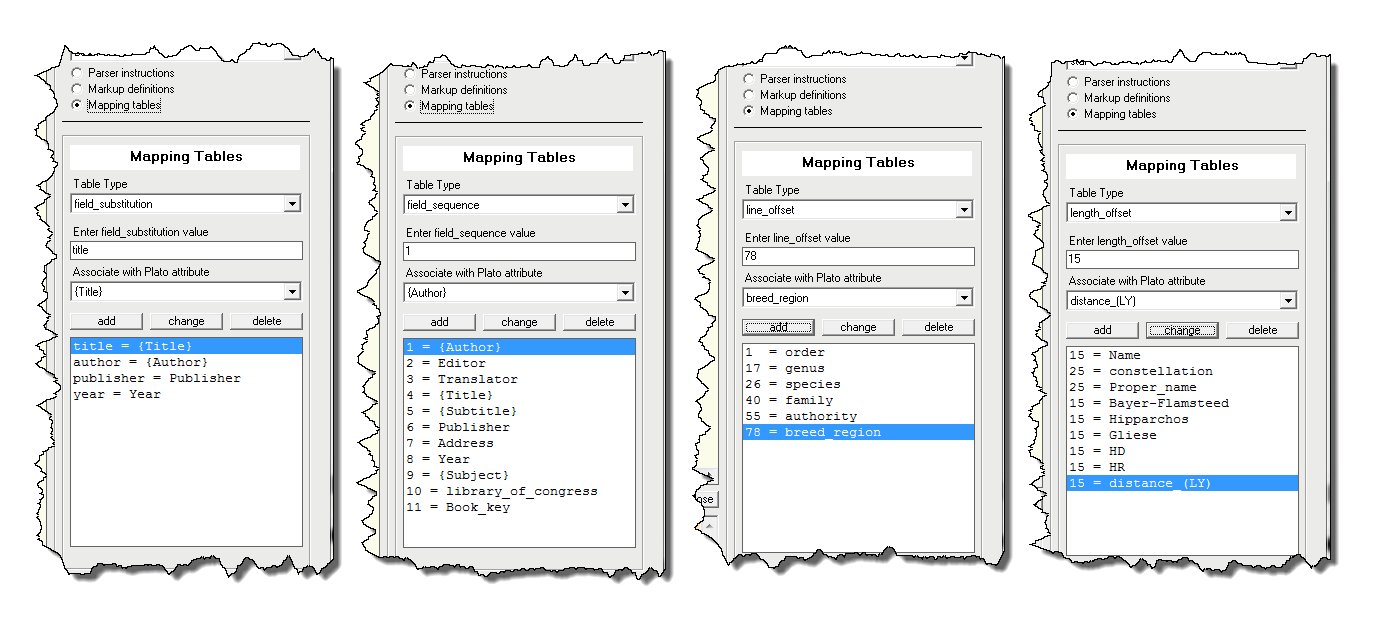
There are four types of mapping tables:- field_substitution Substitution tables are used to translate field names found in the file being parsed to actual object attibute names. Example:
"author name" = author
"year"= publication_date - field_sequence The 'field sequence' type is for delimited files with a record on each line, such as CSV files, in which the order of fields doesn't match the order in the Plato object. For example, the file might look like:
"12345","Jones, Bob","123 Elm Street","555-1212"
"23456","Miller, Bill","234 Oak Street","555-2323"
"34567","Smith, Jack","345 Ash Street","555-3434"
where customer_ID is the first field, followed by name, address, then phone number. But the Plato object might have its attributes placed in a different order, such as:
Name
phone
address
customer_id
A 'field order' table for this file would then be:
2 = name
4 = phone
3 = address
1 = customer_id - line_offset The 'line offset' type is for files with a record on each line, in which the fields are aligned in columns and padded with spaces. Database reports are sometimes structured this way. Such a file might look like this:
Customer ID Name Address Phone
----------- ------------ --------------- ---------
12345Jones, Bob123 Elm Street 555-1212
23456Miller, Bill 234 Oak Street 555-2323
34567Smith, Jack 345 Ash Street 555-3434
A 'line offset' table for this file would be:
1 = customer_id
13 = name
33 = address
55 = phone
This example would take whatever is found from line offsets 1 to 12 and place it in the object's 'customer_id' attribute, and so on to the end of the line. - length_offset The 'field length' type is for binary files that contain fixed-length records of known length and sequence.
|
|
�
| Invoking Import Markup |
|
|
| Figure 7: Using Import Dialogs to Invoke Import Markup |
|
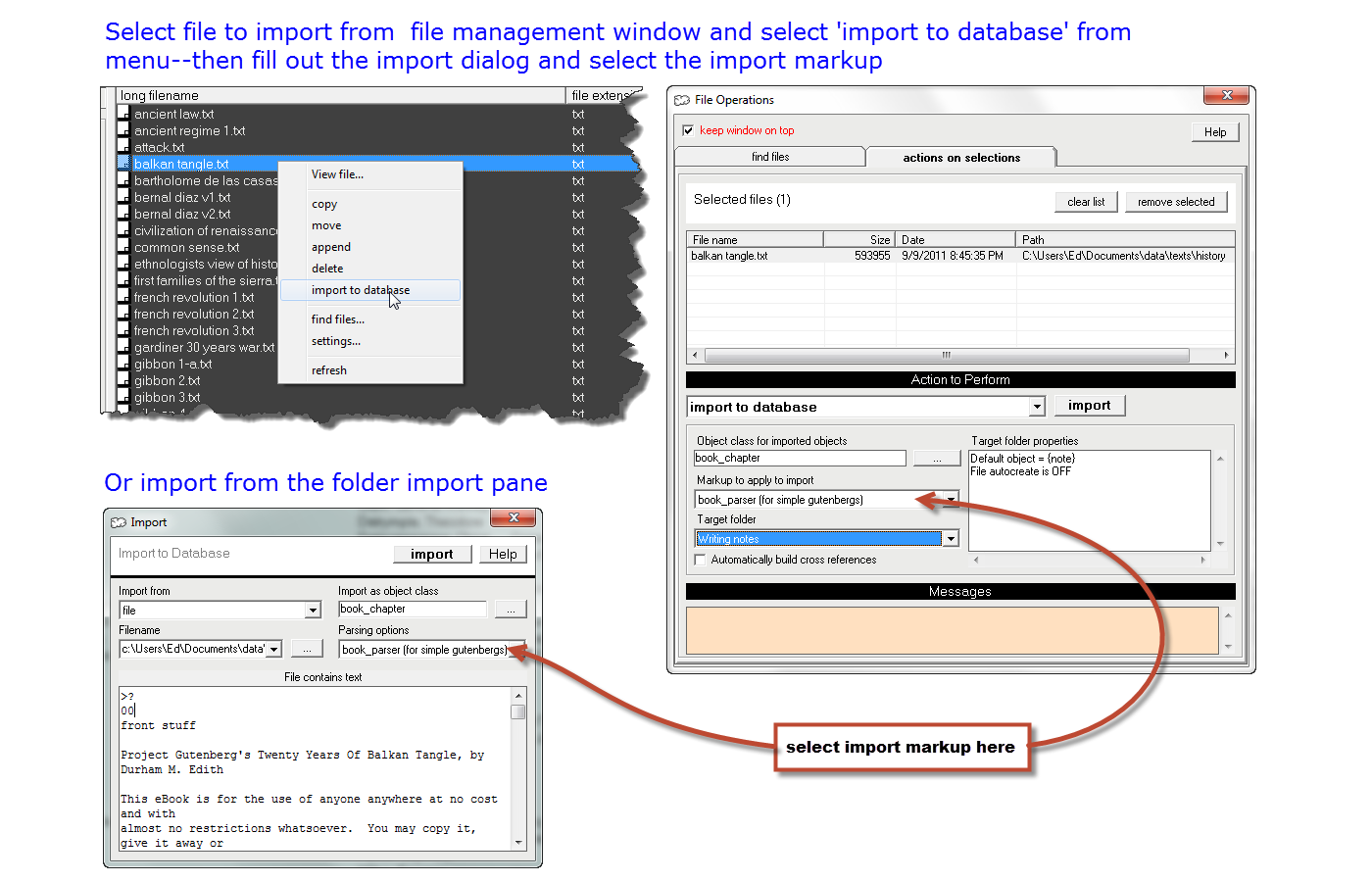
Import markup is put to work when you select a file from the import dialog or the database pane's file management view.
From the folder import pane, you may select either a file or the clipboard. Select the object class you want to create an instance of when you do the import. Then select the parsing option, which will include relevant import markup (when you selected the object class, the parsing option list was automatically tailored to include any import markup that fits the object class you selected). When you press the import button the markup you selected will be used to import the file or clipboard.
From the file management window, select the file (or files--you may select multiple files from this view), right click the mouse to get the context menu, and select "import to database." Select the object class you want to create an instance of when you do the import. Then select the "markup to apply to import" (when you selected the object class, the "markup to apply to import" list was automatically tailored to include any import markup that fits the object class you selected). When you press the import button the markup you selected will be used to import the file (or files).
Note that the objects you import will go into a folder as well as the database. If importing from the folder import pane, the new objects will go into the current folder (i.e., the folder that's open and currently displayed). If importing from the file management window, you must select a target folder from the "target folder" drop down list on the import dialog: that's where the new objects will go. You may want to create a special folder for the import in advance, and select it from the "target folder" drop down before you press the import button.
|
|
� |