| Auto-enumeration | ||

|
||
| Figure 1: Sample Auto Enumeration Output | ||
| Auto-enumerator markup creates auto-enumeration schema for use in scripts. Auto-enumeration schema are of two types: autoenumeration with formatting and autonumeration without formatting. What is being Numbered? For auto-enumeration with formatting, each object processed by the script will be numbered sequentially in the order it is found. If without formatting, each #NUM token will be numbered, not each object. If a script is set to descend cross references or folders, each level is numbered seperately in the sequence in which objects are found. When the script returns to the previous level, numbering for that level will pick up from where it left off. Auto-Enumerated Output Two sample results of markup and autoenumeration schema are shown in figure 1 Here are the autoenumeration schemes that created then: Markup (the same for both A and B): [[object std_organization: 158]] Autoenumeration scheme for A: [GENERAL FORMAT] Autoenumeration scheme for B: [GENERAL FORMAT] |
||
| Auto-enumeration Formatting Conventions | ||
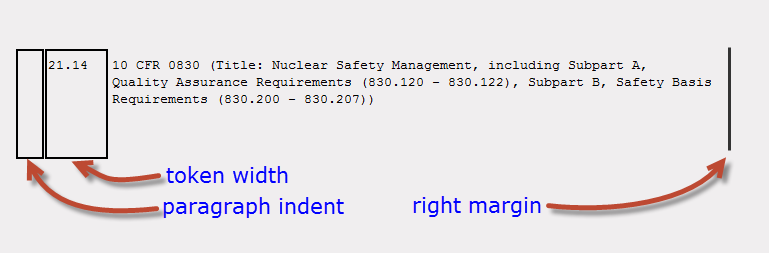
|
||
| Figure 2: Autoenumeration Formatting Convention | ||
| Auto-enumeration with formatting is for creating plain text documents that use fixed-width fonts. It works in conjunction with markup that identifies attributes but has minimal or no other formatting. Auto-enumeration formula take the codes found in the markup and supplies the specified paragraph indents and margins as well as the enuerators. Each auto-enumeration formula contains markup information for each level of nested content that may be encountered in a document. Each formula contains the following fields:
Figure 2 illustrates hoe paragraph indent and token width affect the appearance of the printed page. Auto-enumeration without formatting Auto-enumeration without formatting is for RTF/HTML documents that have their own formatting markup but no auto-enumeration feature. For these documents you must place an auto-enumeration token ([#NUM]) in your markup at the location you want to numbering to appear. The auto-enumeration formula will then look for auto-enumerator tokens and supply the correct paragraph or section numbers, but will not take care of formatting. |
||
| Invoking Auto-enumeration | ||

|
||
| Figure 3: Autoenumeration Drop Down in the Script Pane | ||
| Invoke auto-enumeration via the script editor. Open the script editor and navigate to the output format pane. Select the autoenumeration scheme you want to use from the autoenumeration pull down list at the bottom of the pane (see figure 3). | ||